
You’ll often hear The Freshwater Trust (TFT) stress the importance of data. But it’s not solely about collecting more information.
It’s about using the latest in technology and science to harness the information and make efficient, informed decisions about the management and restoration of our freshwater resources. This is insight.
To read the story the data is telling us, we’re employing an approach called “machine learning.” Stanford defines this as “the science of getting computers to act without being explicitly programmed.” And if it sounds like something out of a sci-fi plot, it did originate in the field of artificial intelligence.
Essentially, machines can be taught to efficiently identify a specific piece of information and reveal patterns.
Most industries where enormous quantities of data are collected, like finance and cyber security, have used it to discover meaningful relationships between variables and significant patterns that are often beyond identification using human-driven processes. You can thank machine learning for self-driving cars, spam filters on email, and facial recognition on Facebook.
How does it work for the worlds of restoration ecology and conservation? TFT uses machine learning to fill data gaps in watersheds that need restoration to improve water quality and native fish habitat.
For example, Light Detection and Ranging (LiDAR) is a remote sensing method that uses light in the form of a pulsed laser to measure variable distances to the Earth, typically from an airplane, and then used by TFT to assess tree canopy in a watershed.

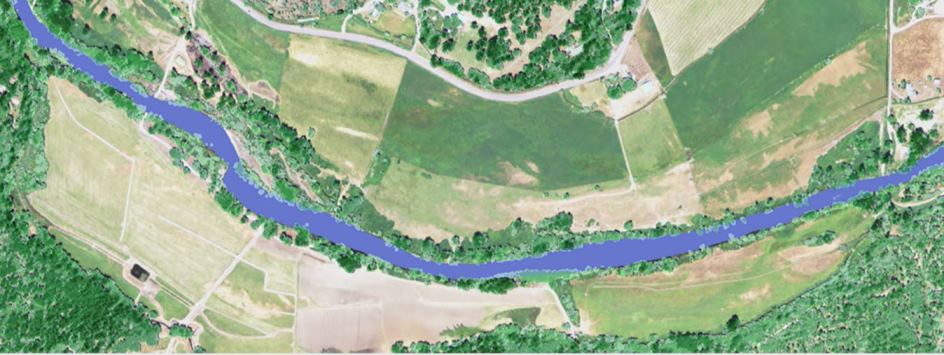
Aerial imagery (top left) is available in all locations and contains important data in the form of the intensity of red, green, and blue that occurs throughout the image. The intensity of these primary colors is one commonly available dataset used to predict canopy height through machine learning when LiDAR data is not available.
Why are we concerned about tree cover? Planting native trees and shrubs in key places along a river creates shade and helps to keep the water cool, making it more hospitable for fish. The streamside vegetation also filters runoff, improving water quality.
When LiDAR data is not available, we still need to assess a watershed to understand where best to plant trees. Without LiDAR, TFT can predict tree canopy heights using data from a nearby watershed with similar conditions where LiDAR data is available.
Through machine learning, the typical canopy height at any given location is “learned” based on the LiDAR-derived heights associated with other variables at the same location – such as elevation, slope, and the exact hue of red, green, or blue in aerial imagery. We are using the other spatial data to teach a computer how to predict tree heights using these other variables.
Then, canopy heights can be predicted across the landscape in the watershed of interest using this data. This results in a full and accurate picture of heights where we can predict existing canopy conditions.
Our analytics team also developed a model that uses a machine learning approach to better understand the benefits of conservation and the impacts of development on a floodplain.
Using a Bayesian network – an approach based on machine learning that allows the relationship between variables in a large dataset to be understood and mapped. In this case, the variable inputs, including data on soil, slope, vegetation and land use are mapped to outputs, such as sediment and nutrient load reduction and water infiltration.
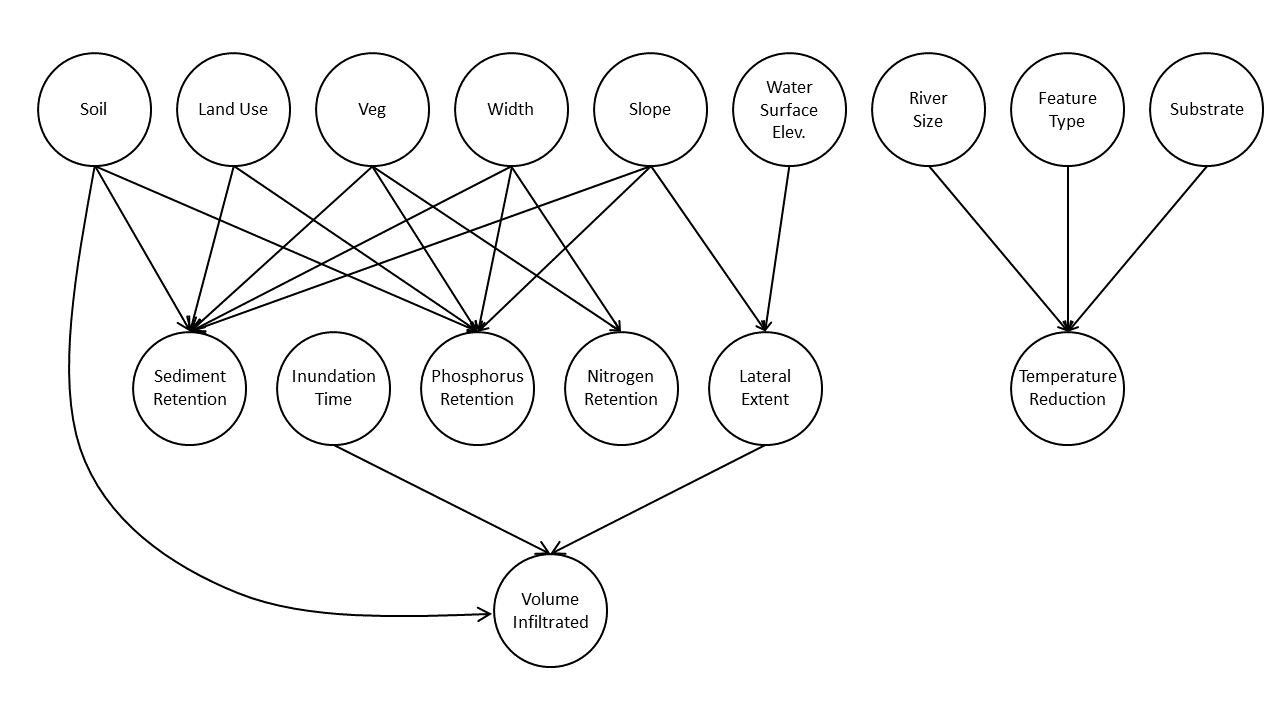
Bayesian network: Map of the relationship between variables in a large data set used by TFT to build a tool to help communities make better decisions about floodplain management. Machine learning algorithms were used to discover the best relationship between these variables out of thousands of potential networks.
With this approach, we were able to create a rapid assessment tool where floodplain managers and project developers can efficiently understand the impacts of their actions.
Thanks in part to machine learning, communities throughout Oregon will be better equipped to make decisions about how to maintain water quality and habitat for salmon in the rivers that run through them.
Are robots, computers and other machines going to fix rivers? Not alone. Machine learning is just one behind the scenes tool to turn data into invaluable insight.
And with insight comes opportunity for action.
This article by Nick Osman originally appeared on Freshwater Trust.